什么是浏览器
浏览器是用来检索、展示以及传递Web信息资源的应用程序。
浏览器有哪些
现如今常见的浏览器有 Chrome 、Firefox 、Edge(Internet Exporler)、 Safari、 Opera。
中国国内的话,还有 QQ浏览器、360浏览器、搜狗浏览器、uc浏览器。
有一些浏览器只在特定的环境下比较流行,比如Konqueror 、Epiphany 、Lynx 等。
浏览器历史
1990年,蒂莫西·约翰·伯纳斯-李爵士(Sir Timothy John Berners-Lee) 开发了第一个网页浏览器 WorldWideWeb,后改名为 Nexus 。 WorldWideWeb 浏览器支持早期的 HTML ,功能比较简单,只能支持文本、简单的样式表、视频、音频、图片等资源的显示。
1993年,马克·安德里森(Marc Lowell Andreessen) 领导的团开发了一个真正有影响力的浏览器 Mosaic,这就是后来世界上最流行的浏览器 Netscape Navigator。
1995年,Microsoft 推出了闻名于世的浏览器 Internet Explorer。
1998年,Netscape 公司开放 Netscape Navigator 源代码,成立了 Mozilla 基金会。
2003年,Apple 公司发布了 Safari 浏览器。
2004年,Netscape 公司发布了著名的开源浏览器 Mozilla Firefox。
2005年,Apple 公司开源了浏览器中的核心代码,基于此发起了一个新的开源项目 WebKit。
2008年, Google 公司以 WebKit 为基础,创建了一个新的浏览器项目 Chromium。以 Chromium 为基础,谷歌发布了 Chrome 浏览器。至于这两者的关系,可以简单地理解为: Chromium 为实验版,具有众多新特性; Chrome 为稳定版。
浏览器功能与特性
现代浏览器主要包含如下几部分的功能与特性:
- 网络 浏览器通过网络模块下载各种资源,如:HTML文档、JavaScript代码、样式表、图片、音频视频文件等。 网络模块是浏览器最重要的模块之一。
- 网页浏览 浏览器最核心的功能。浏览器通过网络下载资源,并从资源管理器获得资源,然后将其转化为可视化结果。
- 资源管理 浏览器通过高效的管理机制来管理网络资源和本地资源。比如如何避免重复下载资源、缓存资源等。
- 多页面管理 浏览器支持多页面浏览,因此支持多页面同时加载。浏览器需要多页面管理机制来解决例如多页面的相互影响和安全等问题。
- 插件和扩展 现代浏览器的重要特征。插件可以用来显示网页特定内容;扩展则是增加浏览器新功能的软件或压缩包。
- 账户和同步 现代软件的普遍特性。浏览器将用户的浏览信息,例如历史记录、书签等信息同步到服务器,提供多系统下的统一体验。
- 安全机制 现代软件的重要特性。浏览器的安全机制需要提供一个安全的浏览环境,例如:避免用户信息被窃取或破坏、防止浏览器被恶意代码攻破等。
- 开发者工具 开发者工具是浏览器提供给网页开发者的工具,可以帮助审查HTML元素、调试JavaScript代码、改善网页性能等。
浏览器系统架构
不同的浏览器在结构方面虽然有所差异,但是整体的设计理念是相似的。因此,可以抽象得到如下图所示的参考结构:
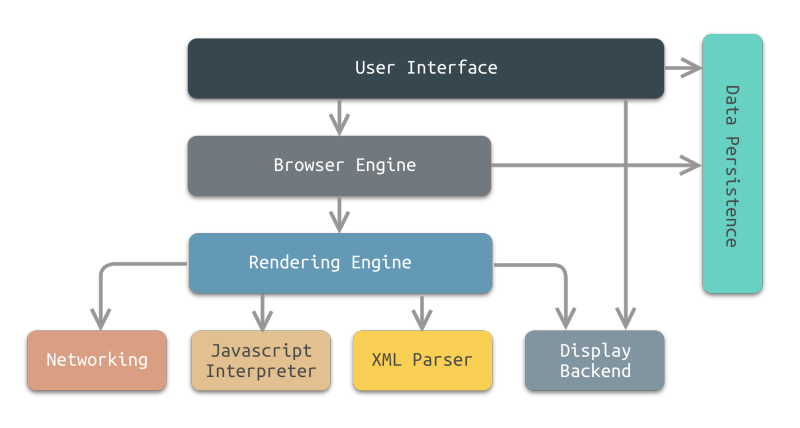
浏览器的抽象分层结构图中将浏览器分成了以下8个子系统:
用户界面(User Interface)
用户界面主要包括工具栏、地址栏、前进/后退按钮、书签菜单、可视化页面加载进度、下载管理、首选项、打印等。
除了浏览器主窗口显示请求的页面之外,其他显示的部分都属于用户界面。
用户界面还可以与桌面环境集成,以提供浏览器会话管理或与其他桌面应用程序通信。
浏览器的用户界面并没有任何正式的规范,但是经过多年来的最佳实践自然发展以及彼此之间相互模仿,浏览器的用户界面有很多彼此相同的元素,其中包括:
- 用来输入 URI 的地址栏
- 前进和后退按钮
- 书签(收藏)设置选项
- 用于刷新和停止加载当前文档的刷新和停止按钮
- 用于返回主页的主页按钮
浏览器引擎(Browser Engine)
浏览器引擎是一个可嵌入的组件,其为渲染引擎提供高级接口。
浏览器引擎可以加载一个给定的URI,并支持诸如:前进/后退/重新加载等浏览操作。
浏览器引擎提供查看浏览会话的各个方面的挂钩,例如:当前页面加载进度、JavaScript alert。
浏览器引擎还允许查询/修改渲染引擎设置。
渲染引擎(Rendering Engine)
渲染引擎为指定的URI生成可视化的表示。
渲染引擎能够显示 HTML 和 XML 文档,可选择 CSS 样式,以及嵌入式内容(如图片)。
渲染引擎能够准确计算页面布局,可使用”回流(重排)/重绘(reflow/repaint)”算法逐步调整页面元素的位置。
网络(Networking)
网络系统实现 HTTP(HTTPS) 和 FTP(SFTP) 等文件传输协议。
网络系统可以在不同的字符集之间进行转换,为文件解析 MIME 媒体类型。
网络系统可以实现最近检索资源的缓存功能。
Firefox 使用了 Necko
JavaScript解释器(JavaScript Interpreter)
JavaScript 解释器能够解释并执行嵌入在网页中的 JavaScript (又称ECMAScript)代码。
Firefox 使用了 SpiderMonkey , Chrome 使用了 V8
XML解析器(XML Parser)
XML 解析器可以将 XML 文档(通常是 HTML)解析成 文档对象模型(Document Object Model,DOM)树。
XML解析器是浏览器架构中复用最多的子系统之一,几乎所有的浏览器实现都利用现有的 XML 解析器,而不是从头开始创建自己的 XML 解析器。
Firefox 使用了 Expat , Chrome 使用了 libXML
显示后端(Display Backend)
显示后端用来绘制基础组件例如组合框和窗口。它抽象了非特定平台的通用接口,在底层会使用操作系统接口方法。
Firefox 使用了 GTK
数据持久层(Data Persistence)
数据持久层将与浏览会话相关联的各种数据存储在硬盘上。这些数据可能是诸如:书签、工具栏设置等这样的高级数据,也可能是诸如:Cookie,安全证书、缓存等这样的低级数据。
浏览器进程架构
早期的浏览器使用单进程的架构,整个浏览器程序在一个进程中运行,用不同的线程来执行不同部分的功能,比如用网络线程来处理网络请求,用插件线程来运行插件,用渲染线程渲染出整个页面。这会有什么问题呢?首先当其中某个线程崩溃,整个浏览器进程就会全部崩掉。其次因为线程可以共享进程资源。所以插件就有可能获取到浏览器运行过程中的数据,就有可能让某些恶意插件获取到网站的敏感数据。
但是慢慢随着技术的发展,web应用的复杂性和重要性都在提升,浏览器技术也需要提升来支撑新的发展。渐渐演化出了多进程的浏览器架构。Chrome/Chromuim 就是基于多进程的架构。在 Chrome 里点击右上角的菜单按钮后选择“更多工具–任务管理器”可以看到浏览器当前使用的进程。
浏览器中的进程:
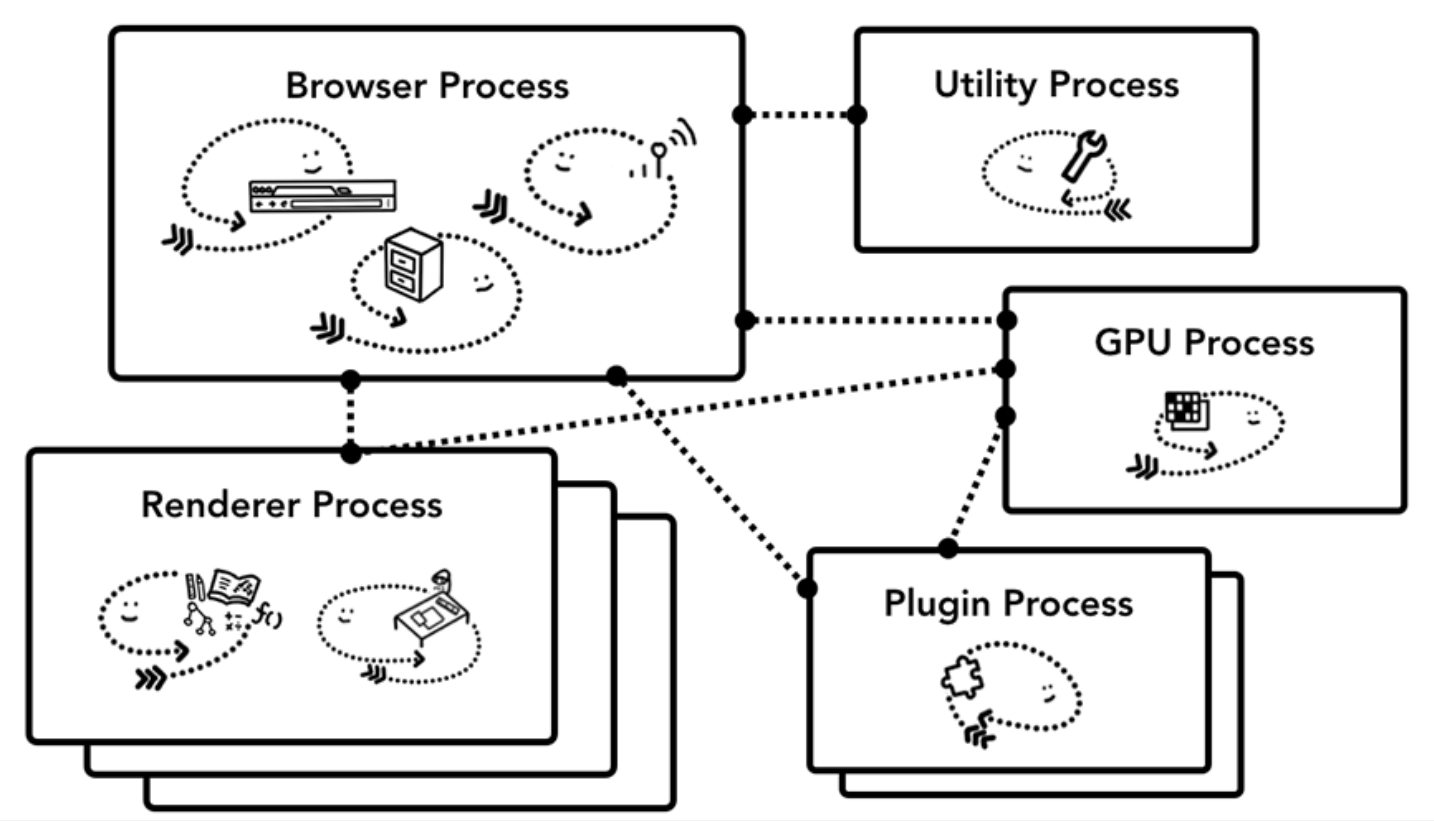
Chrome 中一些进程和它们的作用如下:
- 浏览器主进程(Browser Process):控制浏览器中导航,书签,按钮等可视区域;控制网络请求,文件读写,数据存储等功能;控制子进程的管理、调配和通信。
- 渲染进程(Renderer Process):控制显示网站tab内的所有内容。
- 插件进程(Plugin Process):控制网站使用的所有插件。
- GPU进程(GPU Process):与其他进程隔离地处理GPU任务。
- 其它进程(Other Process):包括扩展进程(Extension)和开发者工具进程(DevTools)或其他服务,比如声音服务(Audio Service)、网络服务(Network Service)、存储服务(Storage Service)等。
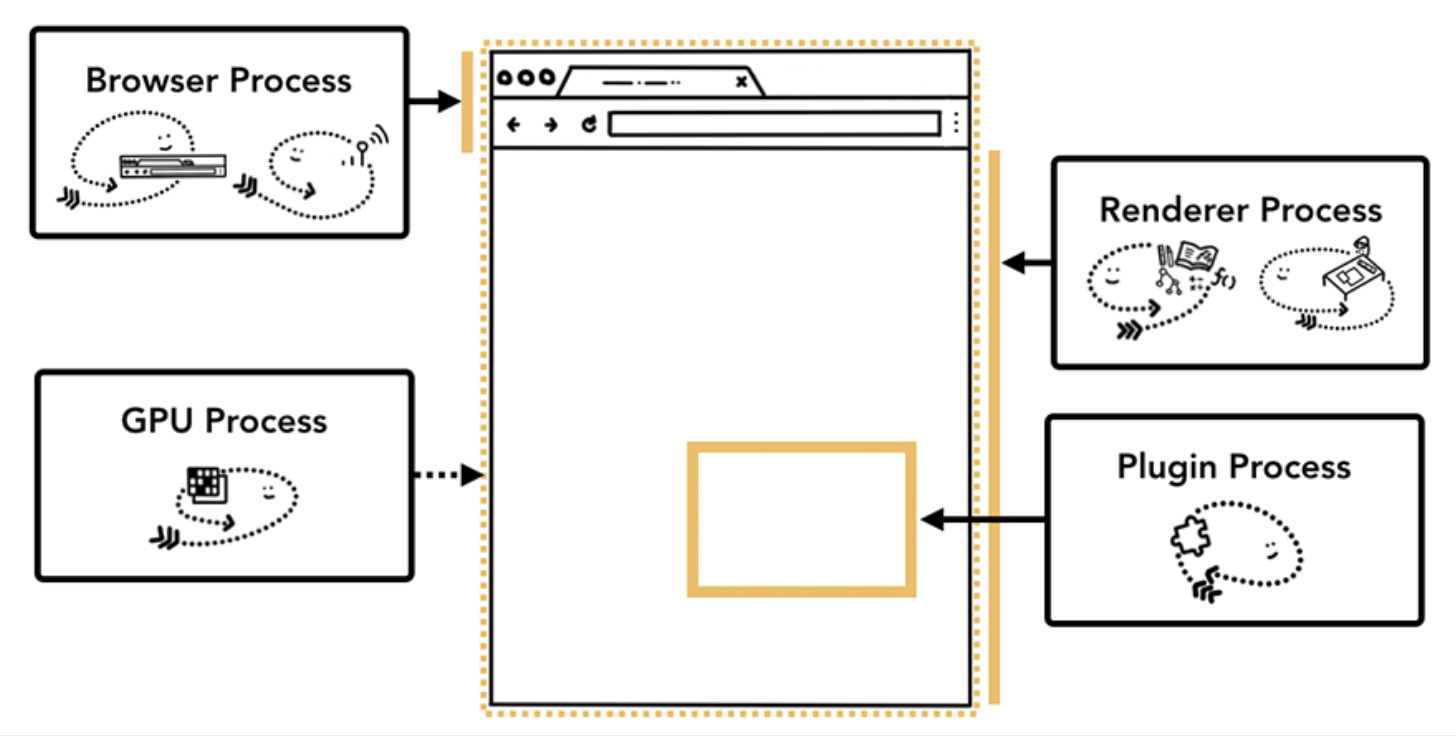
多进程的好处与问题
多进程架构的好处:
- 避免一个tab页面中的崩溃影响到所有的tab页面。
- 安全性和沙盒,因为操作系统提供了限制进程权限的方法,因此浏览器可以对某些功能中的某些进程进行沙箱处理。
多进程的问题:
- 每个进程都会包含公共基础结构的副本(如 JavaScript 运行环境),启动多个进程后,浏览器会消耗更多的内存资源。
Chrome 优化内存的方法:
- Chrome 根据设备的硬件性能限制了可启动的进程数。一旦达到限制后,Chrome 会把在一个网站中的tab页面在同一进程中运行。
- 将浏览器程序的每个部分作为服务运行,这样可以方便拆分或者合并进程。当 Chrome 在性能好的硬件设备上运行时,它可能会将每个服务拆分为不同的进程,从而提供更高的稳定性,但是如果在资源受限的设备上, Chrome 会将服务整合到一个进程中,从而节省了内存。
Chromium 进程模型
Chromium 支持四种不同的模型,它们影响浏览器分配页面给渲染进程的行为。下面对这几种模型进行介绍:
- process-per-site-instance: 为访问网站的每个实例创建一个渲染进程。
首先说一下是什么是网站实例,网站实例是指来自同一网站的连接的页面集合。如果两个页面可以在 JavaScript 代码中获得彼此的引用,就可以把他们认为是连接在一起的。
这种模型的优点有:
- 隔离来自不同网站的内容。页面可以和其他发生错误的页面隔离开来。
- 隔离同一网站的不同tab。在不同tab中独立访问同一网站将创建不同的进程,可以防止失败的实例影响其他实例。
缺点是:
- 更多的内存开销。因为这种模型会创建比较多的渲染进程,虽然可以增加稳定性,但同时也会增加内存开销。
- 实施起来比较复杂。需要复杂的逻辑来支持在网站之间导航时在tab中交换进程,以及处理类似 postMessage 等 JavaScript API。
- process-per-site: 将不同的网站彼此隔离,但是将同一网站的所有实例组合到同一进程中。
这种模型的优点有:
1)隔离来自不同站点的内容。与 process-per-site-instance 模型一样,来自不同站点的页面将不会共享,同时会有更少的内存开销。但与 process-per-site-instance 和 process-per-tab 模型相比,这种模型创建的并发进程可能更少。
缺点是:
1)可能会导致渲染进程过大。比如 google.com 之类的网站托管着各种各样的应用程序,这些应用程序可以在浏览器中同时打开,所有这些应用程序都将在同一渲染进程中渲染。因此,这些应用程序中的资源争用和故障可能会影响许多tab,从而使浏览器的响应性降低。
2)实施起来比较复杂。像 process-per-site-instance 模型一样,这需要用于在导航期间交换流程并代理一些 JavaScript 交互的逻辑。
- process-per-tab: 对每一个tab,用一个渲染进程进行渲染。
和 process-per-site-instance 和 process-per-site 模型在创建渲染器进程时都会考虑内容的来源不同 , process-per-tab 模型将一个渲染进程专用于每个tab。所以它的优点是:
1)简单易懂。每个选项卡都有一个专用的渲染器进程,该进程不会随时间变化。
但是它的缺点为:
1)网站页面之间的共享可能有问题。例如用户将当前tab中的网站导航到其他网站,则新页面将与原先浏览实例中的页面共享。
需要注意的是, Chromium 在 process-per-tab 模型中强制执行安全性时,仍然会强制执行进程交换。例如,不允许普通网页与特权页面(如“设置”和“新标签页”)共享进程。这样就会导致这种模型在实践中并没有比 process-per-site-instance 简单得多。
- single process: 单进程模型,浏览器和渲染引擎都在单个进程中运行。
单进程模型为测量多进程模型性能提供了一个标准。它不是安全或可靠的模型,因为任何渲染线程崩溃都将导致整个浏览器崩溃。它用于测试和开发目的,并且可能包含模型中没有的错误。
浏览器内核
浏览器内核(Browser Core) 在不同的浏览器中定义并不完全一致,但一般包括 Render Engine 和 Browser Engine 的部分,有些也会把 User Interface 和 Data Persistene 也算上。
| 公司 | 浏览器 | 浏览器内核 | js 引擎 |
|---|---|---|---|
| Microsoft | Internet Exporler(IE) -> Edge | Trident(MSHTML,IE11-)->EdgeHTML/MSHTML(Edge)->Blink(基于WebKit) | JScript(IE3.0-IE8.0) -> ChakraCore(IE9+之后)-> v8 |
| Chrome/Chromium | WebKit->Blink(28.0.1469.0+,基于Webkit) | v8 | |
| Apple | Safari | WebKit | JavaScriptCore->SquirrelFish(Nitro) |
| Mozilla | Firefox | Gecko | SpiderMonkey(1.0-3.0)-> TraceMonkey(3.5-3.6)-> JägerMonkey(4.0-)-> IonMonkey (18.0+) -> OdinMonkey(22.0+) |
| Opera | Opera | Elektra(4-6)->Presto(7.0-12.18)->WebKit->Blink(基于Webkit) | Linear A(4.0-6.1)-> Linear B(7.0-9.2)-> Futhark(9.5-10.2)-> Carakan(10.5-)-> V8 |
浏览器工作流程(页面加载过程)
当地址栏输入一个 URL 之后,浏览器会先将 URL 解析成 IP 地址,接着发送 HTTP 请求到对应的 IP 地址请求资源,得到网页资源后,根据类型进行解析,HTML资源将会被解析成 DOM 树,接着将 CSS 样式加载 DOM 树中,生成 Render 树,最后遍历 Render 树来显示内容。
大体上可以分为两块,一部分是网络获取资源,另一部分是渲染。
网络加载
- URI 解析
对地址栏的输入进行解析,如果是一个合法的 URI 则根据协议类型进行对应处理,如果不是,通常现代浏览器会把输入作为搜索关键词,调用对应的搜索引擎进行搜索。若是 HTTP(HTTPS)协议的 URI 则尝试发起 HTTP(HTTPS) 请求。
有关 URI 详情可见 URI-统一资源标志符
- 判断是否使用缓存
浏览器缓存策略依托于 HTTP 协议,故又称 HTTP 缓存策略,详见HTTP 缓存策略
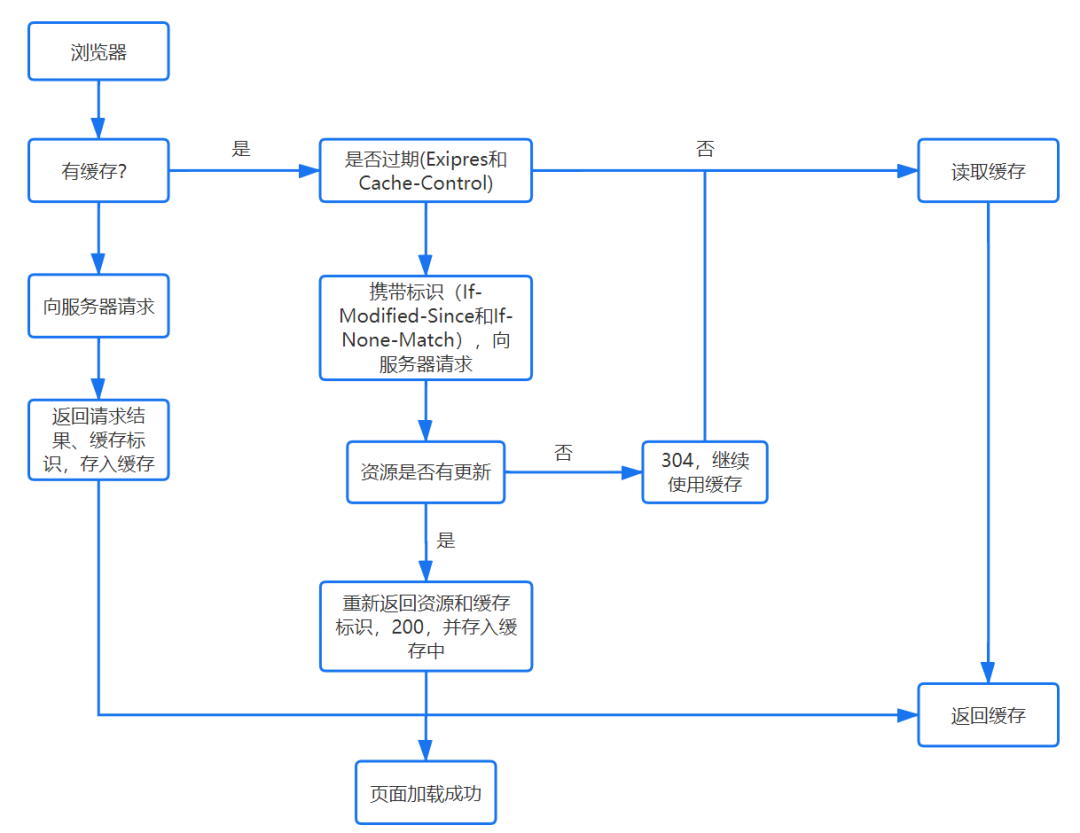
- DNS 查找
浏览器根据 DNS 协议查询 URL 域名对应的 IP 地址,在某个路由表查到结果后就会返回,不再继续继续查询。如果在根域名服务器还查不到 IP 地址,则查询失败。

- 浏览器向服务器发送 HTTP 请求
浏览器与服务器建立 TCP 连接后向服务器发送网络请求。这个过程基于 TCP/IP 协议族,此协议族可分为四层,每层都会对数据进行封装,其大致过程如下图所示:
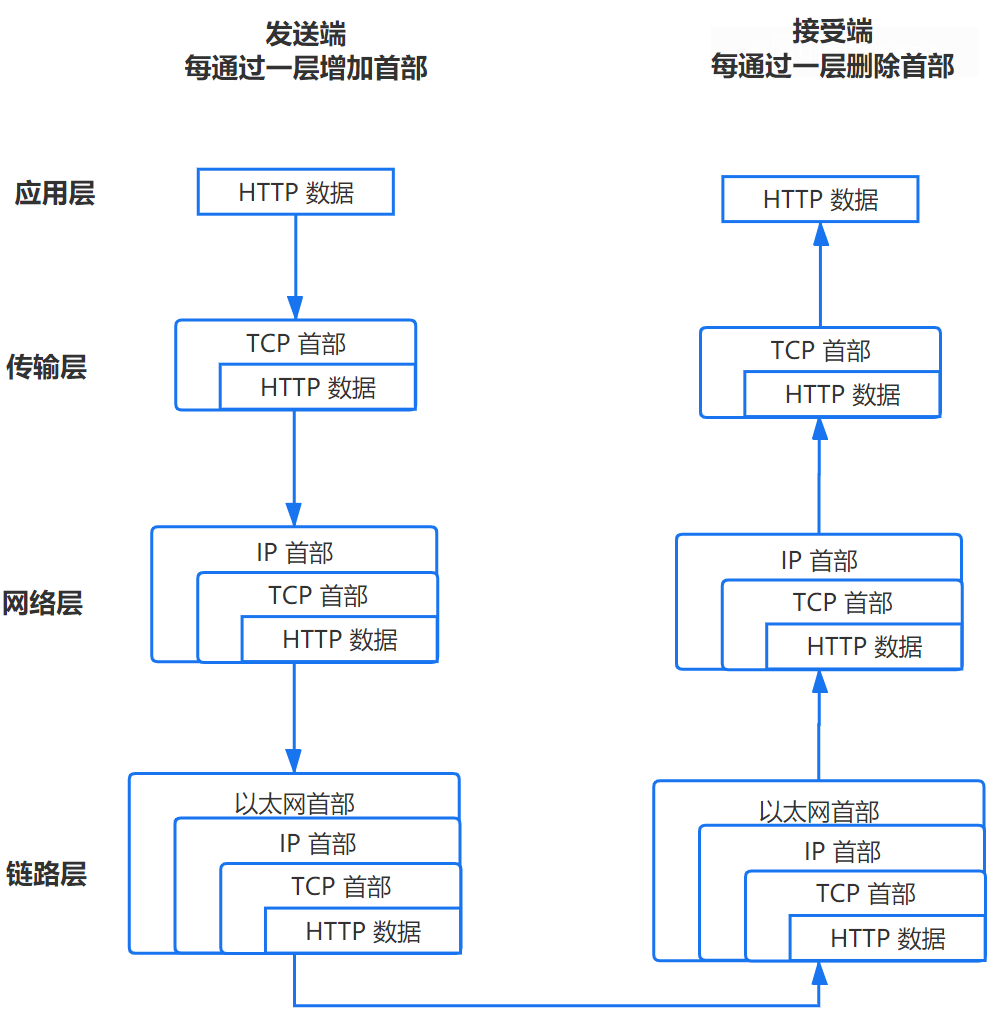
- 服务器处理请求
服务器处理请求的过程因具体实现而异,但大致如下:
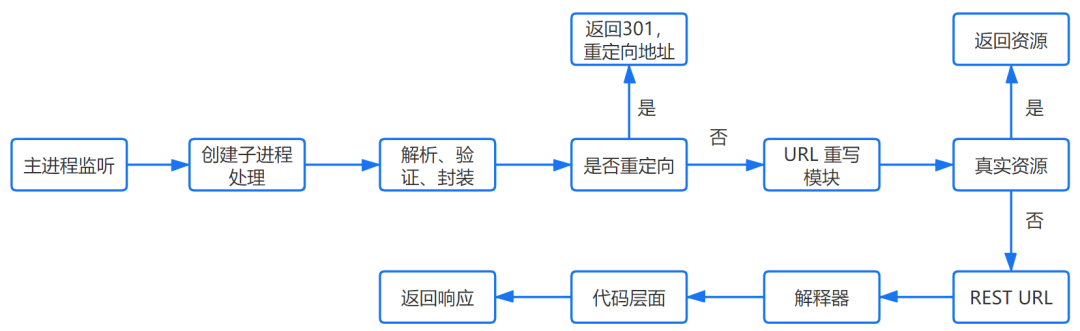
- 浏览器接受响应
浏览器收到服务器的响应后对其进行分析、处理。首先会查看 HTTP 状态码,收到 404 会显示资源不存在的页面、收到 301 会重定向到另一个 URL,各个返回码的含义可参考相关 RFC2616 。如果返回码正常(例如收到了200),则判断是否需要先解压,如果需要则解压,否则根据资源的 MIME 解析内容。
浏览器对相应 HTTP状态码 的响应可以见 HTTP 状态码 。
渲染
渲染引擎的作用是在浏览器的屏幕上显示请求的内容。渲染引擎可显示 HTML 和 XML 文档与图片,甚至可以通过插件支持PDF文档等等。这里,我们将集中介绍他的主要用途:显示使用 CSS 格式化的 HTML 内容和图片。
不同浏览器渲染引擎渲染的整体流程是基本相同的,只是其中的关键步骤术语稍有不同。
webkit 渲染流程如下: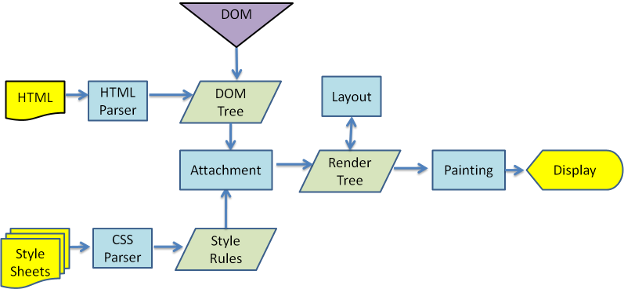
gecko 渲染流程如下: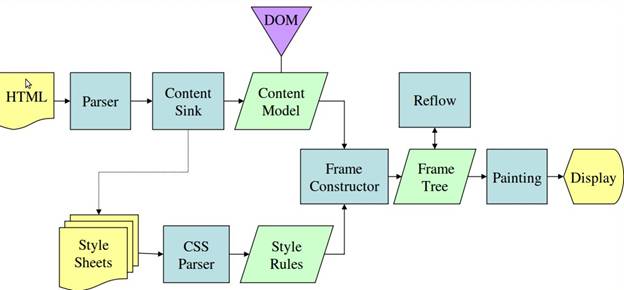
下图所示为渲染引擎的抽象工作流程,以及各个步骤所对应的模块: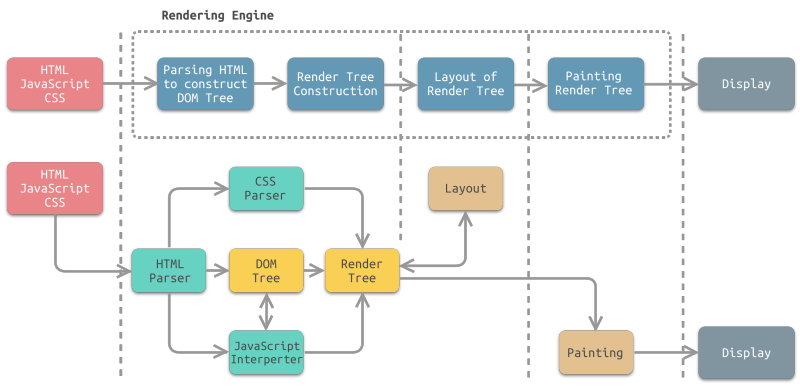
主要有以下几个步骤:
- 将 HTML 解析成结构化的 DOM (文档对象模型 Document Object Model) 树(Parsing HTML to Construct DOM Tree)
渲染引擎使用 HTML 解析器解析 HTML 文档,将各个 HTML 元素逐个转化成 DOM 节点,从而生成 DOM 树。使用 Javascript 解释器解释 Javascript 脚本,变更 DOM 树。同时,渲染引擎使用 CSS 解析器解析外部 CSS 文件以及 HTML 元素中的样式规则生成 CSS Rule 树(也称为CSSOM,CSS Object Model)。 - 渲染树构建(Render Tree construction)
渲染引擎使用第1步 CSS 解析器解析得到的 CSSOM,将其附着到 DOM 树上,从而构成渲染树(Gecko 中称为 框架树 Frame Tree)。渲染树包含多个带有视觉属性(如颜色和尺寸)的矩形。这些矩形的排列顺序就是它们将在屏幕上显示的顺序。 - 渲染树布局(Layout of Render Tree)
渲染树构建完毕之后,进入本阶段进行“布局(Layout or Reflow,中文称回流或重排)”,也就是为每个节点分配一个应出现在屏幕上的确切坐标。 - 渲染树绘制(Painting Render Tree)
渲染引擎将遍历渲染树,并调用显示后代将每个节点绘制(Paint)出来。
参考资料
A Reference Architecture for Web Browsers
《Inside look at modern web browser》

